Native Audio in the Seedance Family, From 2.0 to Mini
generate_audio defaults to true on Seedance 2.0 across every endpoint. Kling v3 Pro splits audio into three pricing tiers. Here is what each pattern costs you and what Mini might inherit.
Native audio is one of the few places where the Seedance family and Kling v3 Pro diverge on philosophy, not just price. Seedance treats audio as part of the render. Kling treats it as a separately billed feature. This post compares the two patterns on the endpoints you can call today, and then says cautiously what Mini is likely to inherit.
What generate_audio: true actually ships on Seedance 2.0
On every Seedance 2.0 endpoint, generate_audio defaults to true. You get a synced audio track baked into the MP4 with no extra parameter and no extra cost. The track includes dialogue when your prompt has a speaking subject, ambient sound for the scene, and foley for on-screen actions. Sample rate is 48kHz stereo.
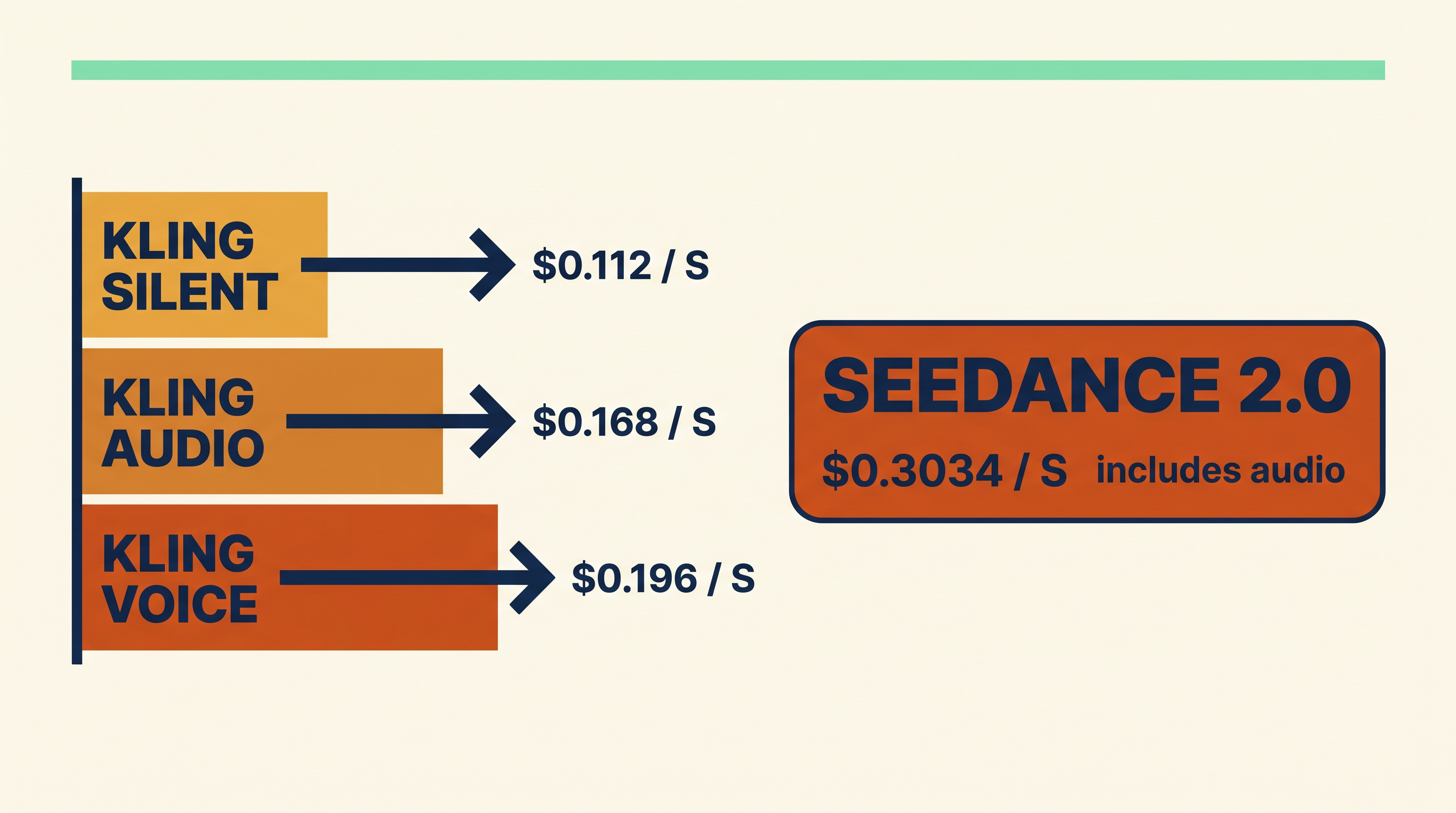
You do not get a separate stem, a music license, or a way to swap the music bed without re-rendering. It is one baked track at the model's per-second rate of $0.3034/s for T2V Standard, plus the token surcharge of $0.014 per 1K tokens.
How to turn it off
The parameter is a single boolean.
01import { fal } from "@fal-ai/client";0203// Silent 8 second clip. Audio comes from a real voice actor in post.04const result = await fal.subscribe("bytedance/seedance-2.0/text-to-video", {05 input: {06 prompt: "Wide shot of a chef plating in a warmly lit kitchen, steam rising, slow push in on the plate.",07 resolution: "720p",08 duration: 8,09 aspect_ratio: "16:9",10 generate_audio: false11 },12 logs: true13});1415console.log(result.data.video.url);
The per-second rate is identical either way. The only difference is latency: audio-on calls run about 15 to 20 percent longer in wall time. On a 500-clip sweep, that adds up.
What audio cues land if you put them in the prompt body
Seedance 2.0 reads audio cues directly from the prompt. A bracketed dialogue line like dialogue: 'Service is on' drives lip sync. Ambient nouns (rain on a tin roof) shape the bed. Foley verbs (a footstep on gravel) show up as on-screen sound effects. The model will not generate music to a named song, mimic a specific voice actor, or extend a track beyond clip duration.
Lip-sync limits
 ByteDance tuned lip sync for Chinese dialects first, with opera and singing as explicit training targets. Multi-speaker works in English, Spanish, Japanese, Korean, and Mandarin. Single-speaker English looks good. Mandarin and Cantonese look notably tighter because that is where the training weight sits. Where it gets wobbly: fast code switching, heavy non-native accents, more than 3 speakers overlapping. If sync drifts, shorten the shot or split dialogue across clips.
ByteDance tuned lip sync for Chinese dialects first, with opera and singing as explicit training targets. Multi-speaker works in English, Spanish, Japanese, Korean, and Mandarin. Single-speaker English looks good. Mandarin and Cantonese look notably tighter because that is where the training weight sits. Where it gets wobbly: fast code switching, heavy non-native accents, more than 3 speakers overlapping. If sync drifts, shorten the shot or split dialogue across clips.
Audio reference inputs
On bytedance/seedance-2.0/reference-to-video, you can attach up to 3 audio tracks (combined under 15 seconds, each file under 15MB). The model uses them to shape timing more than melody: a beat in the bed pulls a cut, a footstep aligns with a step on screen. If you attach audio refs but set generate_audio: false, they still influence motion timing. Useful for silent renders that need to cut to a beat the composer replaces later.
How Kling v3 Pro prices audio
Kling splits audio into a three-tier schedule on fal-ai/kling-video/v3/pro/text-to-video:
- $0.112/s with audio off.
- $0.168/s with audio on.
- $0.196/s with voice control.
A 10 second 1080p clip on Kling runs $1.12 silent, $1.68 with audio, $1.96 with voice control. The same 10 seconds on Seedance 2.0 at 720p runs $3.03 with audio included by default.
That is the philosophical split. Kling lets you opt into audio. Seedance bills audio into the per-second number. For social work that ships with sound, Seedance is one call. For commercial work where a sound designer scores against silent picture, Kling's $0.112/s audio-off rate is the cheaper path.
Speculating about Mini (preview)
Seedance 2 Mini is not live on fal yet. Everything that follows is unverified and tagged Preview.
The most plausible outcome: Mini keeps generate_audio: true as a default. Native audio is the headline feature of the 2.0 line, and dropping it on the lower tier would weaken the split between Mini and the parent. The 15 to 20 percent wall-time overhead matters more on a fast tier, so an audio_priority flag that biases the decoder toward speed might surface. That is a guess, not a roadmap claim.
What will not change on Mini: the prompt-driven audio cue surface. Dialogue lines, ambient nouns, and foley verbs are baked into how the family reads prompts. Mini will read them too.