What Reference-to-Video Tells Us About Mini's Multimodal Story
The Seedance 2.0 reference-to-video endpoint takes 9 image refs, 3 video clips, and 3 audio tracks per call. Mini is in preview, but the pattern the family has already committed to is worth reading.
Seedance 2 Mini is not live on fal yet. The shipping sibling that tells you the most about where the Mini surface will land is bytedance/seedance-2.0/reference-to-video. It is the most distinctive endpoint in the family, and the one most likely to shape what Mini exposes when the endpoint goes public.
The reference budget, spelled out
A single call on bytedance/seedance-2.0/reference-to-video accepts up to 15 reference items total, split across three modalities:
- 9 image references. JPEG, PNG, or WebP. 30MB cap per file.
- 3 video references. MP4 or MOV. Combined runtime 2 to 15 seconds, combined size under 50MB, 480p to 720p source.
- 3 audio references. MP3 or WAV. Combined runtime under 15 seconds, each file under 15MB.
You can submit any subset. An image-only call is fine. So is a single video clip plus one audio cue. The endpoint does not require all three modalities.
How the modalities split work
Image refs set identity and composition. The product, the character face, the wardrobe, the palette. Three to five well-lit images of the same subject from different angles do more than nine images of the same pose.
Video refs set motion. A 2 to 3 second clip of a specific camera arc or body movement steers the output far more than a paragraph of motion language in the prompt. Keep video refs short. Longer clips compete with your output duration for the model's attention.
 Audio refs set rhythm and lip sync. A music bed tells the model where to cut. A voiceover steers mouth movement. Footsteps or impacts give the model an event timing reference.
Audio refs set rhythm and lip sync. A music bed tells the model where to cut. A voiceover steers mouth movement. Footsteps or impacts give the model an event timing reference.
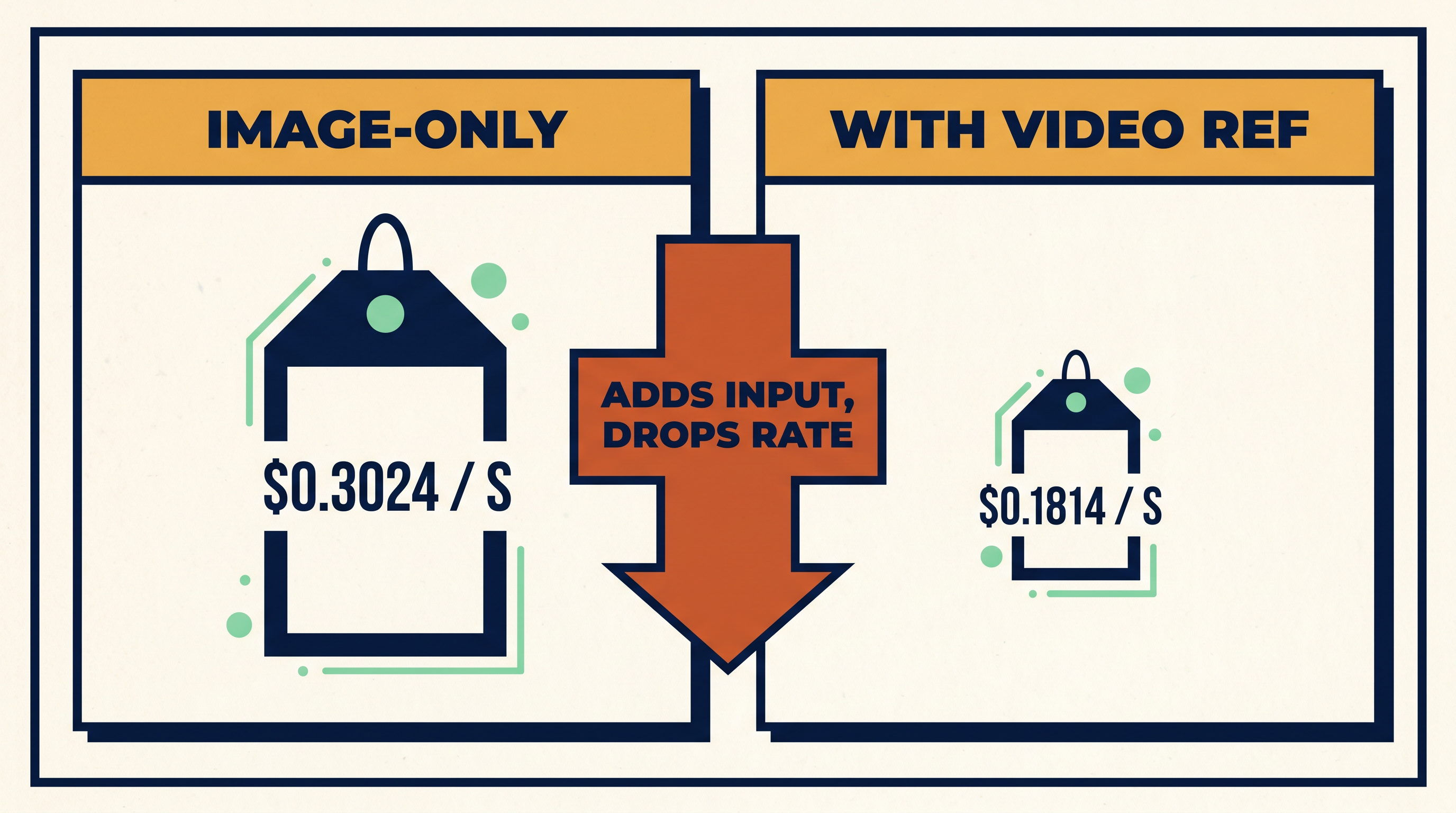
Pricing on the shipping endpoint
Reference-to-video on Standard runs $0.3024 per second of output with image references. When you include video references, the rate drops to $0.1814 per second of output. Token billing matches the rest of the 2.0 family at $0.014 per 1K tokens.
A 6 second 720p output on the image-only path lands at $1.81. The same 6 seconds with a short video reference attached lands at $1.09. That gap is one of the few places in the family where adding inputs reduces your bill.
 ## A working three-image call
## A working three-image call
01import { fal } from "@fal-ai/client";0203// Pin three reference images and let the prompt describe motion.04const result = await fal.subscribe("bytedance/seedance-2.0/reference-to-video", {05 input: {06 prompt: "The subject walks toward camera through a sunlit courtyard, holding the reference product at chest height, slow push in, warm key light from the right.",07 reference_images: [08 "https://v3.fal.media/files/subject-front.jpg",09 "https://v3.fal.media/files/subject-three-quarter.jpg",10 "https://v3.fal.media/files/product-hero.jpg"11 ],12 duration: 6,13 resolution: "720p",14 aspect_ratio: "9:16"15 },16 logs: true17});1819console.log(result.data.video.url);
Three images. One short prompt. Vertical aspect for social. The model holds identity across the 6 seconds because the reference set is consistent, not because the prompt is detailed.
What this tells you about Mini (preview)
Mini is not live yet. Treat every Mini-specific claim that follows as Preview and verify when the endpoint ships.
Most "Mini" tiers in this product family inherit the parent's input shape and trim quality or wall time. The Seedance family has committed to multimodal refs as its differentiating surface, so the most plausible outcome is that Mini ships a bytedance/seedance-2-mini/reference-to-video style endpoint with the same 9/3/3 budget. The argument cuts the other way too: a smaller tier sometimes drops the most expensive modality to keep latency down. If Mini drops video refs, expect image-only stays at 9 with the same 30MB cap.
Audio refs are the most likely cut on a Mini tier, because the audio path is the one with the lowest per-call ceiling already. A Mini that ships image-only references plus native audio defaults would still be a useful tier for the brand work this endpoint already serves.
How to plan for it today
Build your reference workflow against the 2.0 endpoint, not against speculative Mini specs. Lock your image set first. Add a short video reference only when motion is hard to describe in words. Add an audio cue only when timing matters. When Mini lands, swap the endpoint string and re-test the same brief. The reference shape is the part most likely to carry across.